Datasets
Datasets provide a structured way to create, manage, and run test cases for your AI agents, enabling systematic validation and regression testing. Instead of ad-hoc testing, datasets give you repeatable, versioned test suites that ensure your agents work correctly across diverse scenarios.Why Use Datasets?
Consistent testing is crucial for reliable AI agents. Datasets help you:- Build comprehensive test suites with expected outputs
- Run regression tests after changes
- Compare performance across model versions
- Share test cases across your team
- Validate edge cases and failure modes
- Ensure consistent quality before production
Use Cases
- Regression Testing: Ensure updates don’t break existing functionality
- Quality Assurance: Validate agents meet requirements
- Benchmark Creation: Establish performance baselines
- Edge Case Testing: Test unusual or problematic inputs
- Compliance Validation: Verify policy adherence
Creating Datasets
Step 1: Access Dataset Management
Navigate to your agent in the dashboard and click the “Datasets” tab.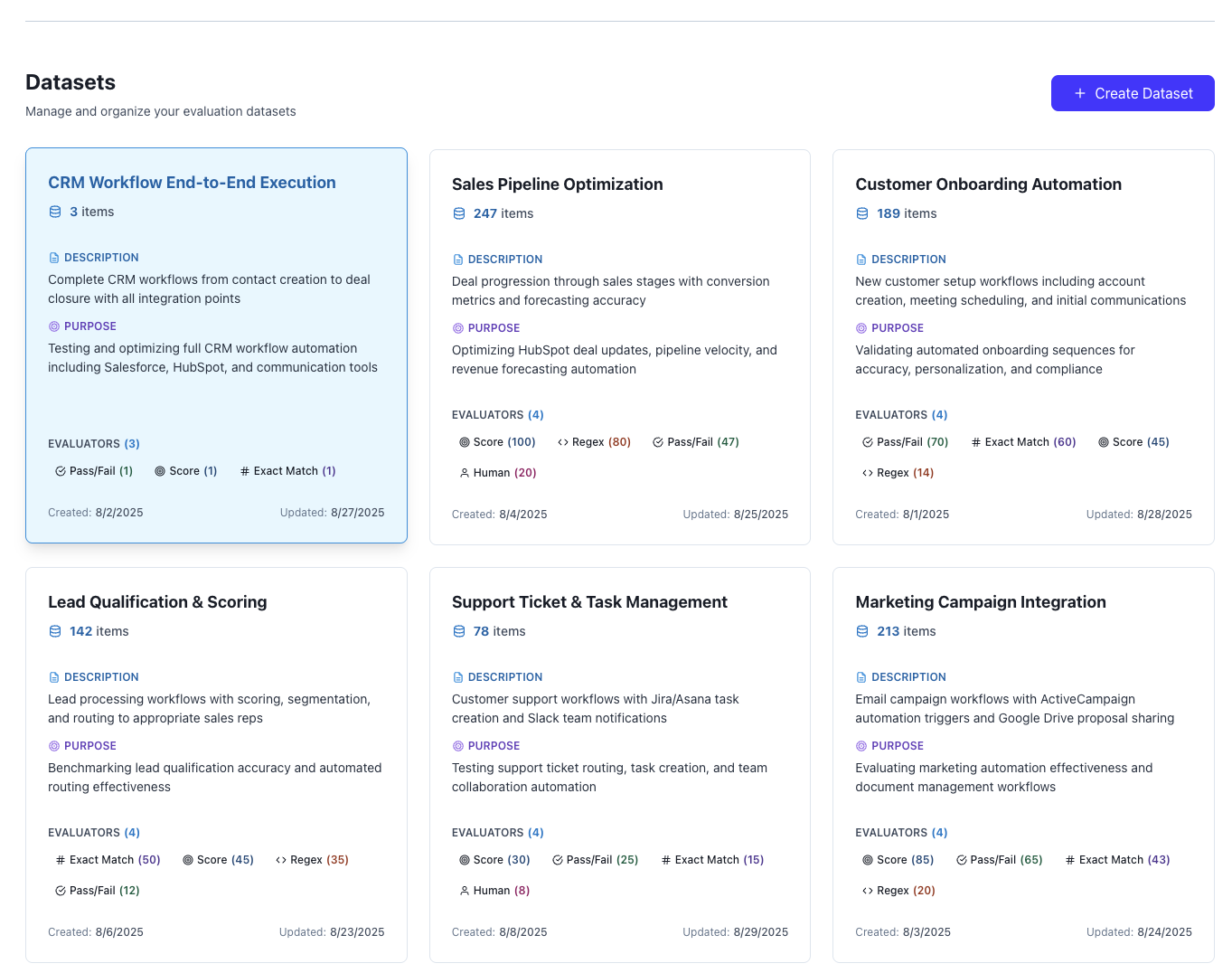
Step 2: Create a New Dataset
Click “Create Dataset” to open the creation dialog: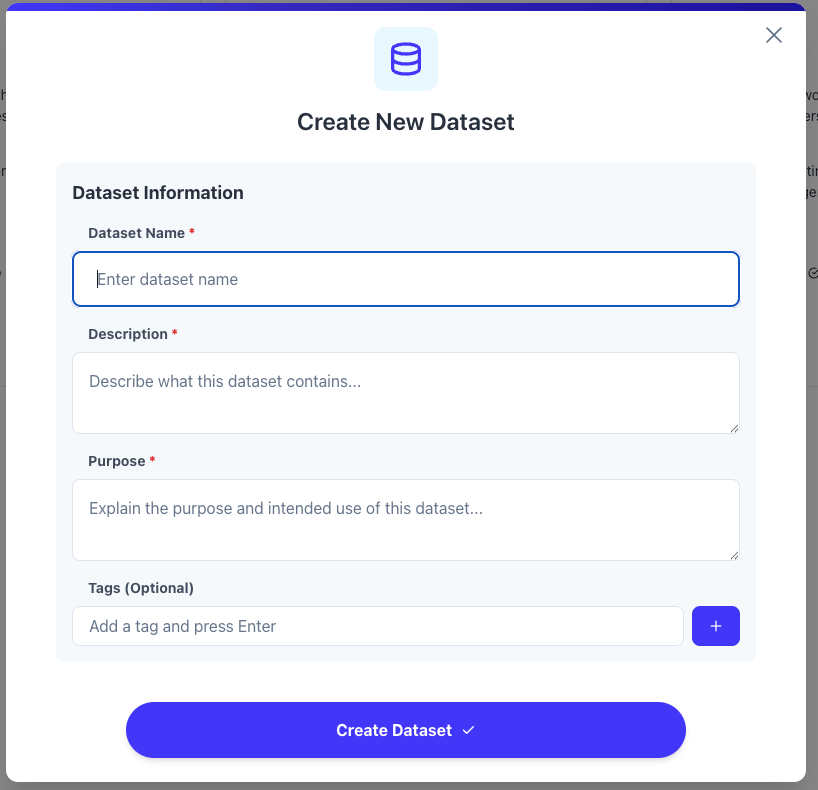
Configuration Options
Basic Information:- Name (Required): Descriptive identifier (e.g., “Customer Support Edge Cases”)
- Description: Detailed explanation of the dataset’s purpose
- Tags: Labels for organization and filtering
- Default Rubrics: Evaluation criteria to apply to all test runs
- Success Criteria: Define what constitutes a passing test
- Timeout Settings: Maximum execution time per test
Dataset Items and Configuration
After creating the dataset, add individual test cases Each dataset item represents a single test case: Required Fields:- Name: Test case identifier (e.g., “Refund request with expired product”)
- Input: The data/prompt to send to your agent
- Expected Output: What the agent should produce
- Description: Context about this test case
- Metadata: Additional data for test execution
- Tags: Categorize test cases within the dataset
Input Format
Inputs can be structured in various formats:Expected Output Format
Define what successful execution looks like:Running Datasets
Programmatic Execution
Batch Execution with Experiments
When you need to run datasets systematically within experiments for A/B testing or comparative analysis, you can leverage batch execution capabilities. Benefits of Batch Execution:- systematic testing: ensures every test case is run consistently
- experiment tracking: all results are grouped under one experiment
- comparative analysis: compare how different configurations handle the same test cases
- automated validation: built-in success/failure tracking per test case
- comprehensive reporting: view results across all test cases in the experiment dashboard
- use descriptive session names that include the test case identifier
- add consistent tags for easy filtering and analysis
- handle errors gracefully to avoid stopping the entire batch
- validate outputs when expected results are defined
- monitor experiment progress through the dashboard
Analyzing Results
Test Run Overview
After running a dataset, view the results dashboard: Summary Metrics:- Pass Rate: Percentage of successful test cases
- Average Duration: Mean execution time
- Cost per Test: Token/API costs
- Failure Categories: Common failure patterns
Individual Test Results
Click on any test case to see:- Full execution trace as session
- Input provided vs output generated
- Evaluation scores from rubrics
- Error messages if failed
- Token usage and costs
- Execution timeline
Comparing Runs
Compare multiple dataset runs to track improvements:- Select runs to compare
- View side-by-side metrics
- Identify regressions or improvements
- Export comparison report
Dataset Versioning
Creating Versions
Datasets automatically version when you:- Add or remove items
- Modify expected outputs
- Change metadata or configuration
Using Versions
Reference specific versions in your tests:Integration with Experiments
Using Datasets in Experiments
Datasets work seamlessly with experiments for A/B testing:- Create an experiment in the dashboard
- Link a dataset to the experiment
- Run the dataset multiple times with different configurations
- Compare results across variants
Automatic Dataset Runs
Configure experiments to automatically run datasets:- On code deployments
- Nightly regression tests
- Before production releases
- After model updates
Best Practices
Dataset Design
Comprehensive Coverage- Include happy path scenarios
- Add edge cases and error conditions
- Test boundary values
- Cover different user personas
- Group related test cases with tags
- Use consistent input/output formats
- Document why each test exists
- Include both positive and negative cases
Expected Outputs
Be Specific When NeededMaintenance
Regular Reviews- Audit datasets quarterly
- Remove obsolete test cases
- Update expected outputs as requirements change
- Add new cases for reported issues
Advanced Features
Dynamic Test Generation
Generate test cases programmatically:Conditional Testing
Run different tests based on conditions:Custom Validation
Implement complex validation logic:Troubleshooting
Common Issues
Dataset items not running- Check input format is correct
- Verify agent can handle the input type
- Ensure no syntax errors in JSON
- Check for required fields
- Review expected output format
- Consider using flexible matching
- Check for extra whitespace or formatting
- Verify output extraction logic
- Use batch execution
- Implement parallel processing
- Consider sampling for quick tests
- Optimize agent code for repeated calls
Tips and Tricks
Quick Wins
- Start with 10-20 core test cases before building comprehensive suites
- Use tags extensively for easy filtering and organization
- Include timing expectations to catch performance regressions
- Document failures as new test cases to prevent regressions
Testing Strategies
- Golden Dataset: Small set of critical tests that must always pass
- Regression Suite: Comprehensive tests run before releases
- Smoke Tests: Quick validation after deployments
- Chaos Testing: Deliberately malformed inputs to test error handling
Collaboration
- Share datasets across team members
- Review test cases in code reviews
- Link datasets to issues for traceability
- Export results for stakeholder reports
Related Features
- Experiments - Run datasets in experiments
- Mass Simulations - Parallel dataset execution
- Rubrics - Evaluation criteria for test runs
- Production Monitoring - Monitor real-world performance
Next Steps
- Create your first dataset with 5-10 test cases
- Run the dataset against your current agent
- Add evaluation rubrics for automated scoring
- Set up regular regression test runs
- Expand coverage based on production issues